Attention Is All We’re Lacking — Implementing Matmul-Less Attention and Transformer Layers¶
This page explains the theory behind AttentionMML and TransformerBlockMML.
Attention Is All You Need¶
The appeal for attention mechanisms kicked off with the seminal paper Attention Is All You Need by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin.
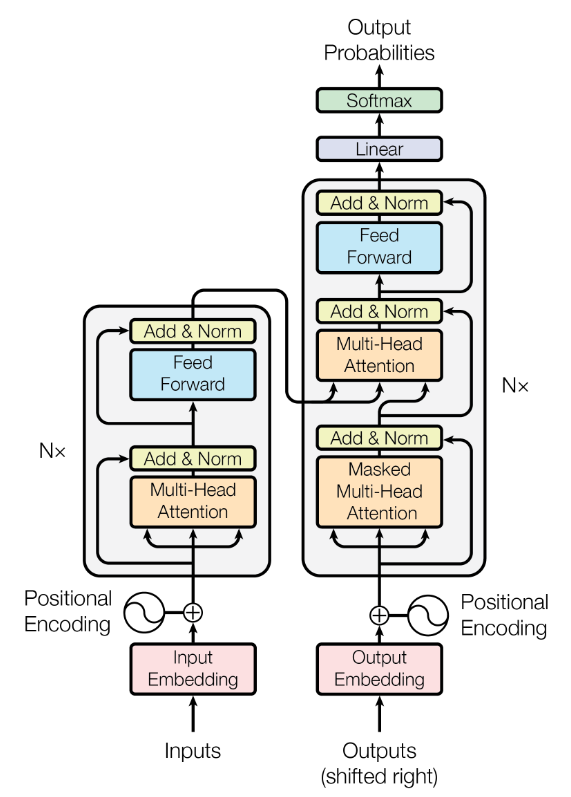
The “attention” refers to the ability of the model to focus on different parts of the input data and determine which components are the most relevant for the task.
Two key concepts introduced in the paper are scaled dot-product attention and multi-headed attention.
Scaled Dot-Product Attention¶
The authors call the attention mechanism introduced in their paper “scaled dot-product attention”, reflecting the fact that
the dot product of two vectors helps measure their similarity; and
scaling is introduced to prevent the values of the dot products (called the attention weights) from getting too big.
Scaled dot-product attention takes in three matrices as input,
the query matrix \(\mathbf{Q}\) representing the queries that the model is “trying to answer”[1];
the key matrix \(\mathbf{K}\) representing the keys that the model is using to “answer the queries”; and
the value matrix \(\mathbf{V}\) which represents the values that the model is “answering”.
The formula for scaled dot-product attention is
The output of this function are weights on the values, where the magnitude of the weights reflects the relative importance of the values.
Multi-Headed Attention¶
Multi-headed attention uses multiple scaled dot-product attention heads in parallel. Each head has its own set of query, key, and value matrices, allowing the model to “answer” different parts of the input in different ways.
Multi-headed attention allows the model to jointly “answer” the questions posed at different positions. With a single attention head, averaging inhibits this; with multiple heads, concatenation makes this possible.
A More General Version of Transformers¶
So why attention? In MetaFormer Is Actually What You Need for Vision by Yu et al., they adopt the perspective that the transformer architecture consists of two parts, a token-mixer and a channel-mixer.
The token-mixer’s job is to mix information among tokens. Concretely, this means that the job of the token-mixer is to allow tokens at a later part of the sequence to “receive” information from tokens in an earlier part of the sequence.
The channel-mixer’s job is to mix embedding or spatial information. This occurs near the end of the model, so as to generate the best embeddings to respond to the task at hand.
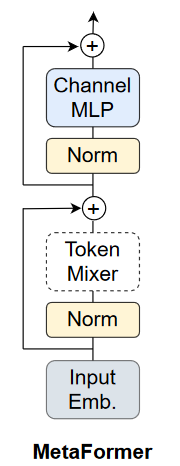
This abstraction of the transformer architecture into what the authors call the MetaFormer architecture opens the door to replace the standard token-mixer (which is often multi-headed attention) with another layer that does a similar job.
Can We Replace Multi-Headed Attention?¶
Another Token-Mixer¶
Scalable MatMul-free Language Modeling by Zhu et al. proposes that Gated Recurrent Units (GRUs) can be used to replace multi-headed attention. Being an architecture that also performs token mixing, and adopting the perspective that MetaFormer is really the main reason for the success of Transformers, Zhu et al. replaces the multi-headed attention with GRUs.
However, the standard implementation of GRUs as described by Cho et al. in Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation makes it hard to parallelize. That was one of the main advantages of multi-headed attention — using multiple heads means that the attention mechanism could be performed simultaneously across multiple heads all at once. To solve this, Zhu et al. considers the approach taken in HGRN2: Gated Linear RNNs with State Expansion and creates a multi-headed variant of GRUs.
A Matrix Multiplication Free Token-Mixer¶
As it stands, however, the GRU architecture still involves matrix multiplications. Using some simple modifications to the processing of information in GRUs, Zhu et al. was able to create \(\mathrm{MLGRU}\), a matmul-less variant of GRUs that is able to harness the power of parallelization via its multi-headed nature. We implemented this as GRUMML.
Matrix Multiplication Free Attention and Transformer¶
Keras-MML agrees with the perspective of Yu et al. that Transformers are one example of the more general MetaFormer architecture. Thus, replacing the standard token-mixer (i.e., multi-headed attention) with that proposed by Zhu et al. (i.e., a matmul-less GRU variant they call \(\mathrm{MLGRU}\) but we call GRUMML), we are justified calling the resulting mechanism an “attention” mechanism. That is why the internal implementation of AttentionMML in Keras-MML uses GRUMML behind the scenes — GRUMML acts as a suitable replacement for multi-headed attention as a token-mixer.
As for TransformerMML, the only difference made is to replace the attention mechanism with AttentionMML and to replace any matrix multiplications with ternary weights. In particular, the feed-forward network part of the transformer is largely unchanged, except that we adopt a Swish-activated Gated Linear Unit (SwiGLU) for the channel-mixer (which is almost the same as a normal feed-forward network).